|
|
|||||||||||


 |
|
|
Опции темы | Опции просмотра |
|
|
|||||||||||
|
|
|
Опции темы | Опции просмотра |
|
#1
 02.09.2021, 14:06
02.09.2021, 14:06
|
|||
|
|||
|
Google опубликовала в своём блоге исследование специалистов из внутренней команды Brain Team, озаглавленное как «Создание высокоточных изображений с использованием моделей диффузии». В статье исследователи рассказывают о новых достижениях, которые они сделали в области масштабирования цифровых изображений без потери качества.
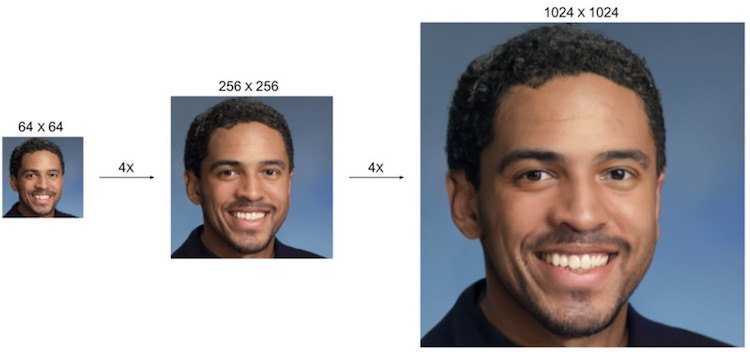 Специалисты Google Brain Team натренировали модель машинного обучения превращать фотографии с низким разрешением в детализированные изображения с высоким разрешением практически без потери качества. Эксперты считают, что их разработка может использоваться в самых разных целях: от улучшения старых семейных фото до повышения качества медицинских изображений.  Концепция диффузионных моделей изучается Google с 2015 года, однако до недавнего времени поисковый гигант отдавал предпочтение другому семейству методов обучения ИИ — глубоким генеративным моделям. Компания обнаружила, что результаты нового подхода заметно превосходят существующие технологии.  Новый подход получил обозначение SR3. Google говорит, что SR3 — это модель диффузии со сверхвысоким разрешением, которая создаёт изображение с высоким разрешением из чистого шума, опираясь на исходную картинку с низким разрешением. Модель обучается процессу искажения изображения, при котором шум постепенно добавляется к изображению до тех пор, пока не останется только чистый шум. Затем алгоритм обращает процесс вспять, постепенно удаляя шум, с изображения, руководствуясь исходной картинкой с низким разрешением. 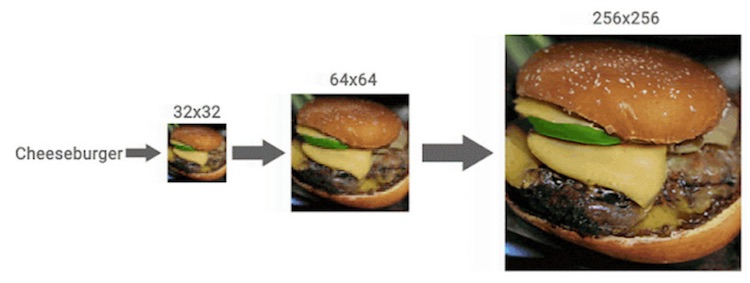 Было обнаружено, что наилучшие результаты SR3 демонстрирует при масштабировании портретов и снимков природы. Алгоритм позволяет добиться фотореалистичного изображения при повышении разрешения портретов до шестнадцати раз. 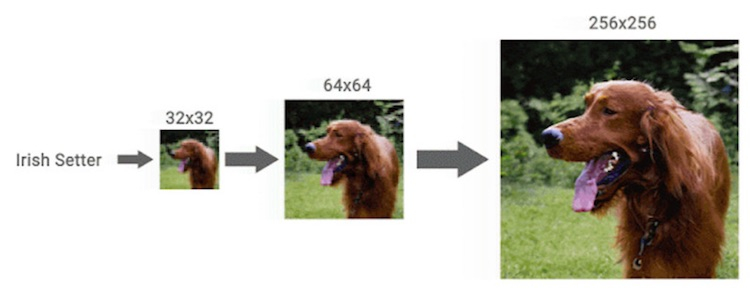 Как только Google убедилась, насколько эффективна SR3, компания пошла ещё дальше, предложив ещё один подход под названием CDM, который представляет собой модель условно-классовой диффузии. CDM обучена на данных ресурса ImageNet, содержащего более 14 миллионов изображений с высоким разрешением. CDM предлагает каскадный подход, при котором сначала генерируется изображение с низким разрешением, за которым следует работа SR3 по созданию изображений с высоким разрешением, которое постепенно повышается до максимально возможного. По данным Google, изображение с разрешением 32 × 32 пикселя может быть увеличено до 256 × 256 пикселей без ощутимых потерь, в восемь раз. Картинку с разрешением 64 × 64 пикселя и вовсе удалось масштабировать до разрешения 1024 × 1024 пикселя, в 16 раз. Результаты работы ИИ действительно впечатляют. Окончательные изображения, несмотря на мелкие огрехи, выглядят действительно очень хорошо и большинством пользователей воспринимаются как оригинальные снимки.
__________________
Учение свет, а тьма повсюду 

|
| Этот пользователь поблагодарил microsoftexam(а) за это полезное сообщение: | ||
saran149 (02.09.2021) | ||
|
#2
02.09.2021, 22:30
|
||||
|
||||
|
Это больше похоже на неправду, либо что-то недоговаривают об алгоритме и его возможностях. Увеличение разрешения фото с улучшением качества невозможно, т.к. информация утеряна. Её нет. Человеческий мозг конечно может попытаться восстановить изображение в некотором роде, это можно пронаблюдать, если посмотреть на "пиксельное" изображение прищурившись. Мозг отобразит вам улучшенное изображение, но это происходит из-за личного интеллекта, т.е. мозг может понимать, что это лицо и может "дорисовать" его исходя из логики лица. И то, даже мозг не может четко восстановить детализацию зубов и глаз, что уж говорить про алгоритм. Заложить это в алгоритм, мне думается, это вряд ли возможно. Скорее невозможно. На "пиксельном" изображении девушки видно, что невозможно было из него восстановить четкое изображение, т.к. такая прорисовка зубов с такими острыми краями, а так же бликов в глазах невозможна, т.к. на исходном фото этой информации просто нет, она отсутствует. Если только не идет речь про конкретный алгоритм распознающий только лица, т.е. если в алгоритм заложены примерная логика лица и возможные варианты. И опять же где та грань соотношения худшего изображения к лучшему, т.е. если скажем размер 1024х1024 еще можно превратить в 2048х2048 некими сплайнами и диффузаторами, то где логика, что начальным размером можно взять размер 256х256 или вообще 32х32. Неужели взяв картинку 32х32 они смогут нарисовать 2048х2048. Это же бред. Т.е. там либо есть какие-то ограничения, либо речь про конкретные образы, либо это ложь. Если же речь идет не только про лицо, а про что угодно, то это вообще больше похоже на ложь.
__________________
Золотая серединка - лучшее всему решение
|
|
#3
02.09.2021, 22:32
|
||||
|
||||
|
Цитата:
__________________
Бойтесь Бога и воздавайте хвалу ему, ибо приближается час суда его... Телега - https://t.me/siberian_life Группа там же - https://t.me/pogovorimrub
|
|
#4
02.09.2021, 22:35
|
||||
|
||||
|
Чтобы понимать, надо знать суть нейронок.
Вот та же нейронка от гугла фото отрабатывает: НС хорошо отрабатывает на тех примерах, на которых обучалась.
__________________
 Люблю линуксоидов за их красные глаза и злую веру в светлое будущее Люблю линуксоидов за их красные глаза и злую веру в светлое будущее
|
|
#5
03.09.2021, 16:44
|
|||
|
|||
|
Я тоже думаю, что дип фейки и все такое очень многое может уже. ИИ еще конечно в стадии зарождения, но уверен, что он легко будет справляться с подобными задачами, тут главное иметь базу всех вещей на планете и лиц))))
__________________
Учение свет, а тьма повсюду
|
|
#6
03.09.2021, 17:35
|
||||
|
||||
|
Я больше скажу: ИИ сейчас нет вообще. То подобие слабого ИИ, что сейчас есть - это нейронные сетки. Не нужно их путать с ИИ.
__________________
Люблю линуксоидов за их красные глаза и злую веру в светлое будущее
|





 Линейный вид
Линейный вид

